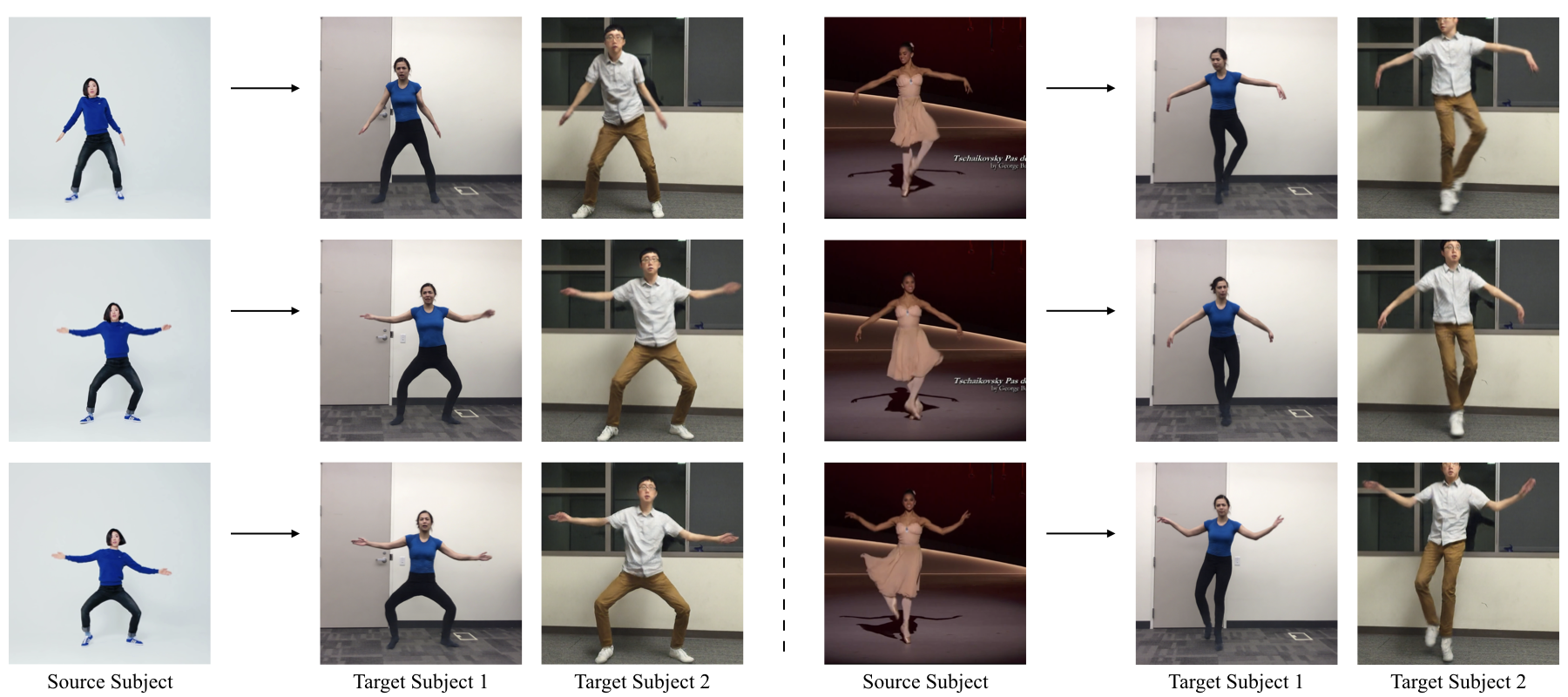
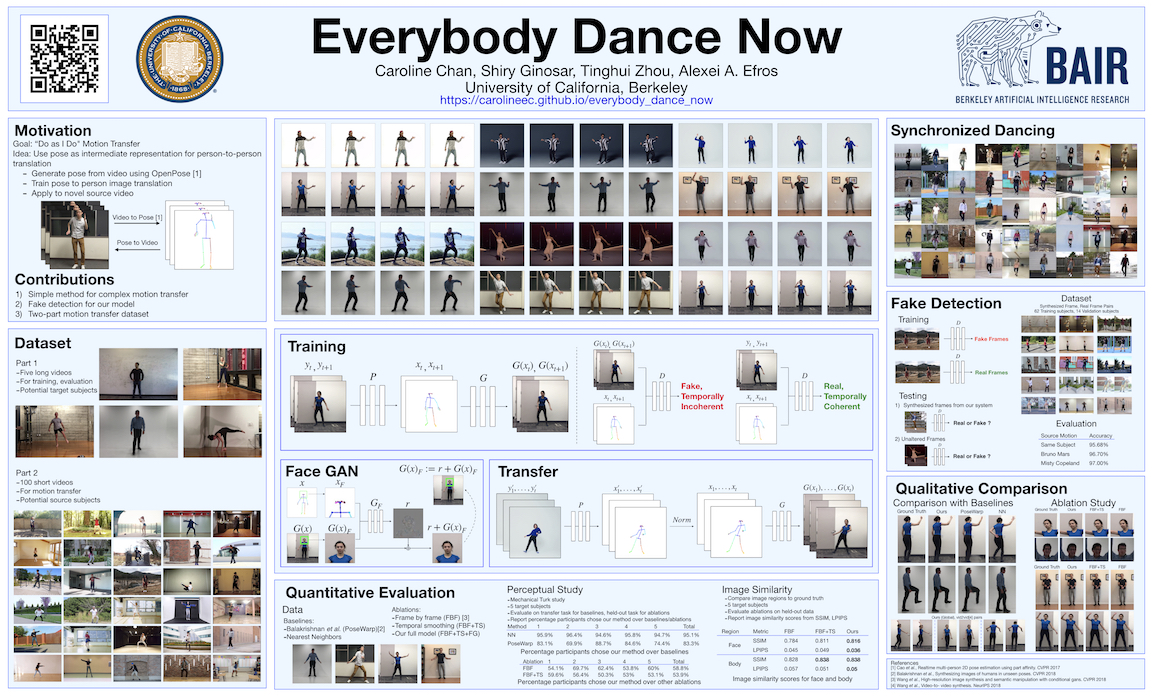
This paper presents a simple method for "do as I do" motion transfer: given a source video of a person dancing, we can transfer that performance to a novel (amateur) target after only a few minutes of the target subject performing standard moves. We approach this problem as video-to-video translation using pose as an intermediate representation. To transfer the motion, we extract poses from the source subject and apply the learned pose-to-appearance mapping to generate the target subject. We predict two consecutive frames for temporally coherent video results and introduce a separate pipeline for realistic face synthesis. Although our method is quite simple, it produces surprisingly compelling results (see video). This motivates us to also provide a forensics tool for reliable synthetic content detection, which is able to distinguish videos synthesized by our system from real data. In addition, we release a first-of-its-kind open-source dataset of videos that can be legally used for training and motion transfer. Our video demo can be found here.
Paper
Everybody Dance Now Caroline Chan, Shiry Ginosar, Tinghui Zhou, Alexei A. Efros
ICCV, 2019
[hosted on arXiv]
We present a two-part dataset: First, long single-dancer videos that can be used to train and evaluate our model. All subjects have consented to allowing the data to be used for research purposes. We specifically designate the single-dancer data to be high-resolution open-source data for training motion transfer and video generation methods. We release a large collection of short YouTube videos we used for transfer and fake detection. Download our dataset here.
This work was supported, in part, by NSF grant IIS-1633310 and research gifts from Adobe, eBay, and Google. This webpage template was borrowed from here.
*C. Chan is currently a graduate student at MIT CSAIL.
**T. Zhou is currently affiliated with Humen, Inc.